 Small-sized Unmanned Surface Vehicle (USV) equipped with various sensors used for data acquisition.
Small-sized Unmanned Surface Vehicle (USV) equipped with various sensors used for data acquisition.
Unmanned Surface Vehicle
Unmanned surface vehicles (USVs) are small-sized robotic boats which require a high-level of autonomy for their safe navigation. These vessels are ideal for operation in coastal waters and narrow marinas due to their portability, and can be used for automated inspection of hazardous and difficult-to-reach areas.
For our research purposes we have used USV developed by HarphaSea d.o.o. The USV has a steerable thrust propeller with a small turn radius, and reaches a maximum velocity of 2.5 m/s. It is equipped with an on-board computer, a compass, GPS unit, IMU unit and a pixel-synchronized stereo system Vrmagic VRmMFC, which consists of two Vrmagic VRmS-14/C-COB CCD sensors, Thorlabs MVL4WA lens with 3.5 millimeters focal length, maximum aperture of f/1.4, and a 132.1 degrees FOV. The stereo system is mounted 0.7 meter above the water surface with baseline at 0.2 meter, resulting in depth estimation range up to 185 meters. Stereo cameras are connected to the on-board computer through USB-2.0 bus and are thus capable of capturing the video of resolution 1278x958 pixels at 10 frames per second.
Marine Semantic Segmentation Training Dataset (MaSTr1325) [5]
MaSTr1325 is a new large-scale marine semantic segmentation training dataset tailored for development of obstacle detection methods in small-sized coastal USVs. The dataset contains 1325 diverse images captured over a two year span with a real USV, covering a range of realistic conditions encountered in a coastal surveillance task. All images are per-pixel semantically labeled and synchronized with inertial measurements of the on-board sensors. In addition, a dataset augmentation protocol is proposed to address slight appearance differences of the images in the training set and those in deployment.
General Overview
Over the course of two years, the USV was manually guided in the gulf of Koper, Slovenia, covering a range of realistic conditions typical for coastal surveillance and encountering a large variety of obstacles. From more than fifty hours of footage acquired, we have hand-picked representative images of a marine environment. A particular attention was paid to include various weather conditions and times of day to ensure the variety of the captured dataset. Finally, 1325 images were accepted for the final dataset. Images in the dataset are time-synchronized with measurements of the on-board GPS and IMU.
The obstacles in the dataset cover a wide range of shapes and sizes. Some of the obstacles present in the dataset are:
- cargo ships,
- sail boats,
- portable piers,
- swimmers,
- rowers,
- bouys,
- seagulls, ...
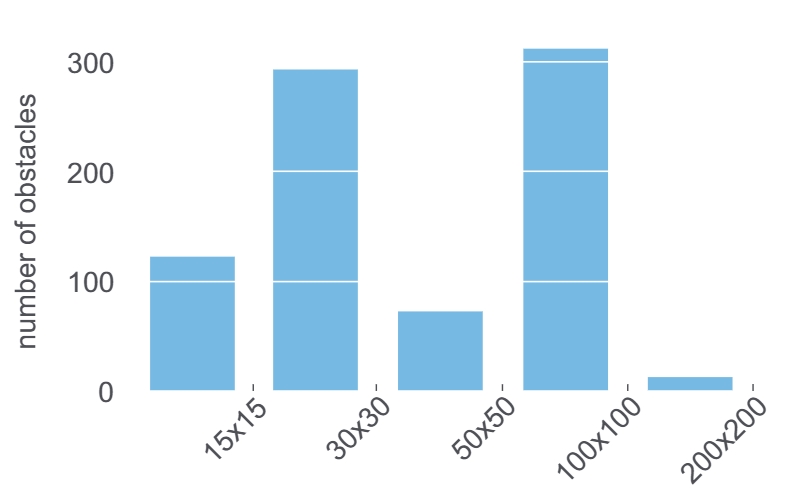 Size distribution of obstacles.
Size distribution of obstacles.
Labeling
Each image from the dataset was manually annotated by human annotators with three categories (sea, sky and environment). An image editing software supporting multiple layers per image was used and each semantic region was annotated in a separate layer by multiple sized brushes for speed and accuracy. All annotations were carried out by in-house annotators and were verified and corrected by an expert to ensure a high-grade per-pixel annotation quality. The annotation procedure and the quality control took approximately twenty minutes per image. To account for the annotation uncertainty at the edge of semantically different regions, the edges between these regions were labeled by the unknown category. This label ensures that these pixels are excluded from learning.
Labels in ground-truth annotation masks correspond to the following values:
- Obstacles and environment = 0 (value zero)
- Water = 1 (value one)
- Sky = 2 (value two)
- Ignore region / unknown category = 4 (value four)




Data Augmentation
In practice, we can realisticlly expect that the camera exposure and other parameters at application time differ from those used in the dataset acquisition. Data augmentation helps us effectively induce a regularization effect in the learning process. We thus propose applying the following data augmentations:
- vertical mirroring,
- central rotations of +/- [5, 15] degrees,
- elastic deformation of the water component,
- color transfer.
Downloads
The dataset is publicly available for download:
↓ MaSTr1325 Images [1278x958] (soon)
↓ MaSTr1325 Ground Truth Annotations [1278x958] (soon)
↓ MaSTr1325 Images [512x384]
↓ MaSTr1325 Ground Truth Annotations [512x384]
↓ MaSTr1325 IMU Masks [512x384]
Cite the paper
Multi-modal Marine Obstacle Detection Dataset 2 (MODD2) [3]
MODD2 is currently the biggest and the most challenging multi-modal marine obstacle detection dataset captured by a real USV. Diverse weather conditions (sunny, overcast, foggy), extreme situations (abrupt change of motion, sun gliter and reflections) and various small obstacles all contribute to its difficulty.
General Overview
Multi-modal Marine Obstacle Detection Dataset 2 (MODD2) consists of 28 video sequences of variable length, amounting to 11675 stereo-frames at resolution of 1278x958 pixels each. The dataset was captured over a period of approximately 15 months in the gulf of Koper, Slovenia, using our acquisition system. During the dataset acquisition, the USV was manually guided by an expert, who was instructed to simulate realistic navigation scenarios with situations in which an obstacle may present a danger to the USV. Such situations include sailing straight in the direction of an obstacle, and sailing in the near proximity of an obstacle. To maximize the visual diversity of the environment, the dataset was recorded over a period of several months at different times of day and under various weather conditions. All sequences are time-synchronized with the measurements of the on-board sensors: IMU, GPS and compass.
There are three different extreme situations present in the dataset which affect the quality of computer vision algorithms and sensor calibration algorithms:
- sudden change of motion,
- sun glitter,
- reflections.
Twenty-seven out of 28 sequences contain at least one occurrence of an obstacle. The distribution of obstacle sizes and obstacle occurrence per video sequence is shown on graphs.
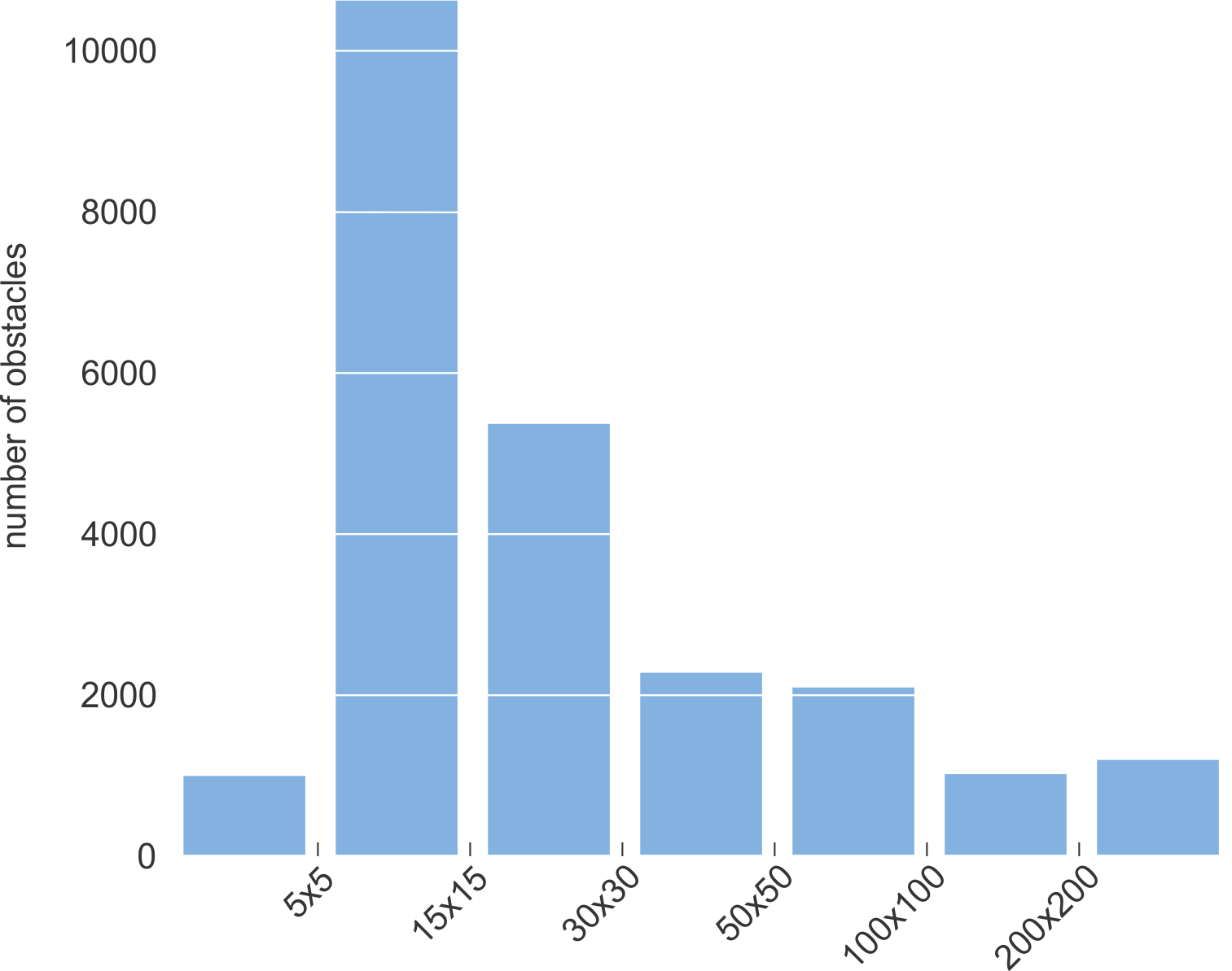
Size distribution of obstacles for RAW images.
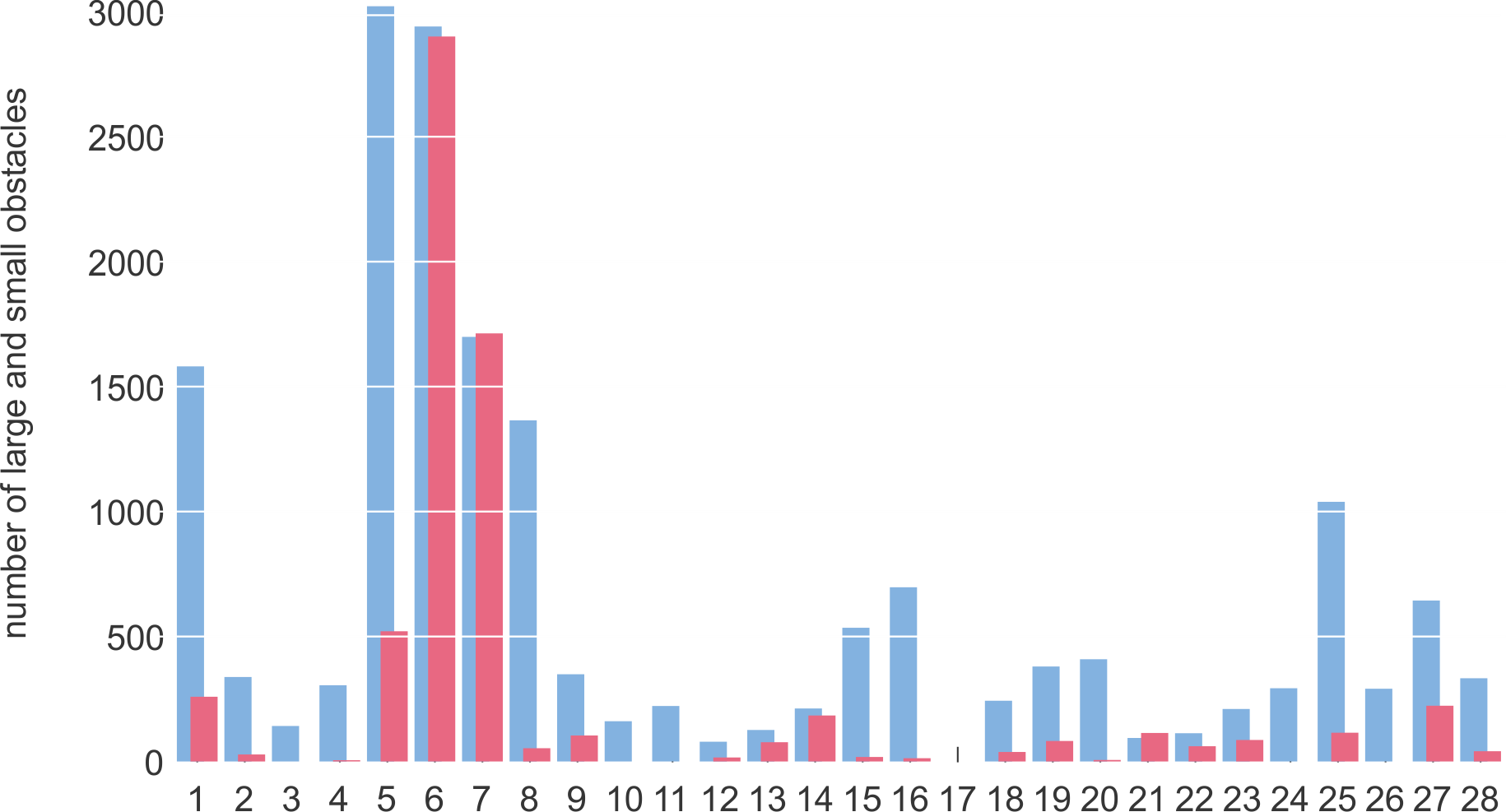
Distribution of large (cyan) and small (light red) obstacles in each sequence for RAW images.
Labeling
Each frame in the dataset was manually annotated by a human annotator and later verified by an expert. The edge of water is annotated by a polygon, while obstacles are outlined with bounding boxes. The annotated obstacles are further divided into two classes:
- large obstacles (whose bounding box straddles the sea edge) --- highlighted with cyan color,
- small obstacles (whose bounding box is fully located below the sea edge polygon) --- highlighted with light-red color.



Evaluation Protocol
We use performance measures inspired by Kristan et al. [11]. The accuracy of the sea-edge estimation is measured by mean-squared error and standard deviation over all sequences (denoted as μedg and σedg respectively). The accuracy of obstacle detection is measured by number of true positives (TP), false positives (FP), false negatives (FN), and by F-measure.
To evaluate RMSE in water edge position, ground truth annotations were used in the following way. A polygon, denoting the water surface was generated from water edge annotations. Areas, where large obstacles intersect the polygon, were removed. This way, a refined water edge was generated. For each pixel column in the full-sized image, a distance between water edge, as given by the ground truth and as determined by the algorithm, is calculated. These values are summarized into a single value by averaging across all columns, frames and sequences.
The evaluation of object detection follows the recommendations from PASCAL VOC challenges by Everingham et al. [9], with small, application-specific modification: detections above the annotated water edge are ignored and do not contribute towards the FP count as they do not affect the navigation of the USV. In certain situations a detection may oscillate between fully water-enclosed obstacle and the dent in the shoreline. In both cases, the obstacle is correctly segmented as non-water region and it can be successfully avoided. However, in first scenario the obstacle is explicitly detected, while second scenario provides us with only indirect detection. To address possible inaccuracies causing dents in the water-edge, the overlap between the dented region and obstacle is defined more strictly as that of water-enclosed obstacles. Note that the proposed treatment of detections is consistent with the problem of obstacle avoidance.
Video showcase of sequences in MODD2. All obstacles are outlined with a yellow bounding-box, where large obstacles and small obstacles are highlighted with cyan and light-red color respectively. A dotted pink polygon marks the water-edge.
Downloads
The dataset and evaluation/visualization scripts are publicly available for download:
↓ MODD2 Video Data and IMU Measurements (RAW images)
↓ MODD2 Video Data and IMU Measurements (rectified and undistorted images)
↓ MODD2 Calibration Sequences
↓ MODD2 Ground Truth Annotations (for RAW images)
↓ MODD2 Ground Truth Annotations (for rectified and undistorted images)
↓ MODD2 Masks of Visible Parts of the USV
↓ MODD2 GPS Data
↓ MODD2 Segmentation Evaluation Functions (Matlab)
↓ MODD2 Detections Visualization Functions (Matlab)
Cite the paper
Multi-modal Marine Obstacle Detection Dataset 2 LeaderBoard
The performance of proposed methods (ISSMmono [2], ISSMstereo [3], IeSSM [4]) as well as the performance of state-of-the-art segmentation methods (SSM [11], SegNet [1], PSPNet [13], DeepLab2 [6], DeepLab3+ [7] and BiSeNet [12]) was evaluated on the MODD2. SSM, ISSM, and IeSSM depend on simple features (pixel RGB color and position), run on CPU and operate with 100x100 pixels input images. Alternatively, CNN methods use rich features, run on GPU and operate with 512x384 pixels input images. All CNN methods were trained using a RMSProp optimizer with a momentum 0.9, initial learning rate 10-4 and standard polynomial reduction decay of 0.9. The weights of their common ResNet-101 backbone were pre-trained on ImageNet [8], while the remaining additional trainable parameters were randomly initialised using Xavier [10]. The networks were fine-tuned on augmented training set for five epochs.
In the evaluation procedure we have set the minimal overlap between bounding-boxes to 0.15, disabled the freezone under the water-edge and set the size of the smallest acceptable obstacle to a surface of 5x5 pixels. The experiments were performed on raw and distorted images as well as rectified and undistorted images. Exceptions are ISSM and IeSSM which strictly require rectified and undistorted images for their operation.
Results on Raw and Distorted Images
| Method | Water-edge accuracy [pixels] | TP | FP | FN | F-measure [percent] |
|---|---|---|---|---|---|
| PSPNet [13] | 13.8 (16.0) | 5886 | 4359 | 431 | 71.1 |
| SegNet [1] | 13.5 (18.5) | 5834 | 2138 | 483 | 81.7 |
| DL2noCRF [6] | 12.8 (21.4) | 3946 | 227 | 2371 | 75.2 |
| DL3+ [7] | 14.1 (20.9) | 5311 | 2935 | 1006 | 72.9 |
| BiSeNet [12] | 12.4 (19.2) | 5699 | 1894 | 618 | 81.9 |
Total number of obstacles for evaluation: 6317
Results on Undistorted and Rectified Images
| Method | Water-edge accuracy [pixels] | TP | FP | FN | F-measure [percent] |
|---|---|---|---|---|---|
| ISSMmono [2] | 52.8 (62.9) | 1865 | 3442 | 3584 | 34.7 |
| ISSMstereo [3] | 52.8 (62.9) | 1828 | 105 | 3621 | 49.5 |
| IeSSM [4] | 55.0 (65.5) | 2276 | 151 | 3173 | 57.8 | PSPNet [13] | 13.7 (16.1) | 5131 | 3919 | 318 | 70.8 |
| SegNet [1] | 13.2 (16.6) | 5106 | 1852 | 343 | 82.3 |
| DL2noCRF [6] | 12.3 (17.5) | 3482 | 211 | 1967 | 76.2 |
| DL3+ [7] | 13.6 (17.4) | 4797 | 2338 | 652 | 76.2 |
| BiSeNet [12] | 12.1 (16.8) | 5014 | 1667 | 435 | 82.7 |
Total number of obstacles for evaluation: 5449
Qualitative Comparison
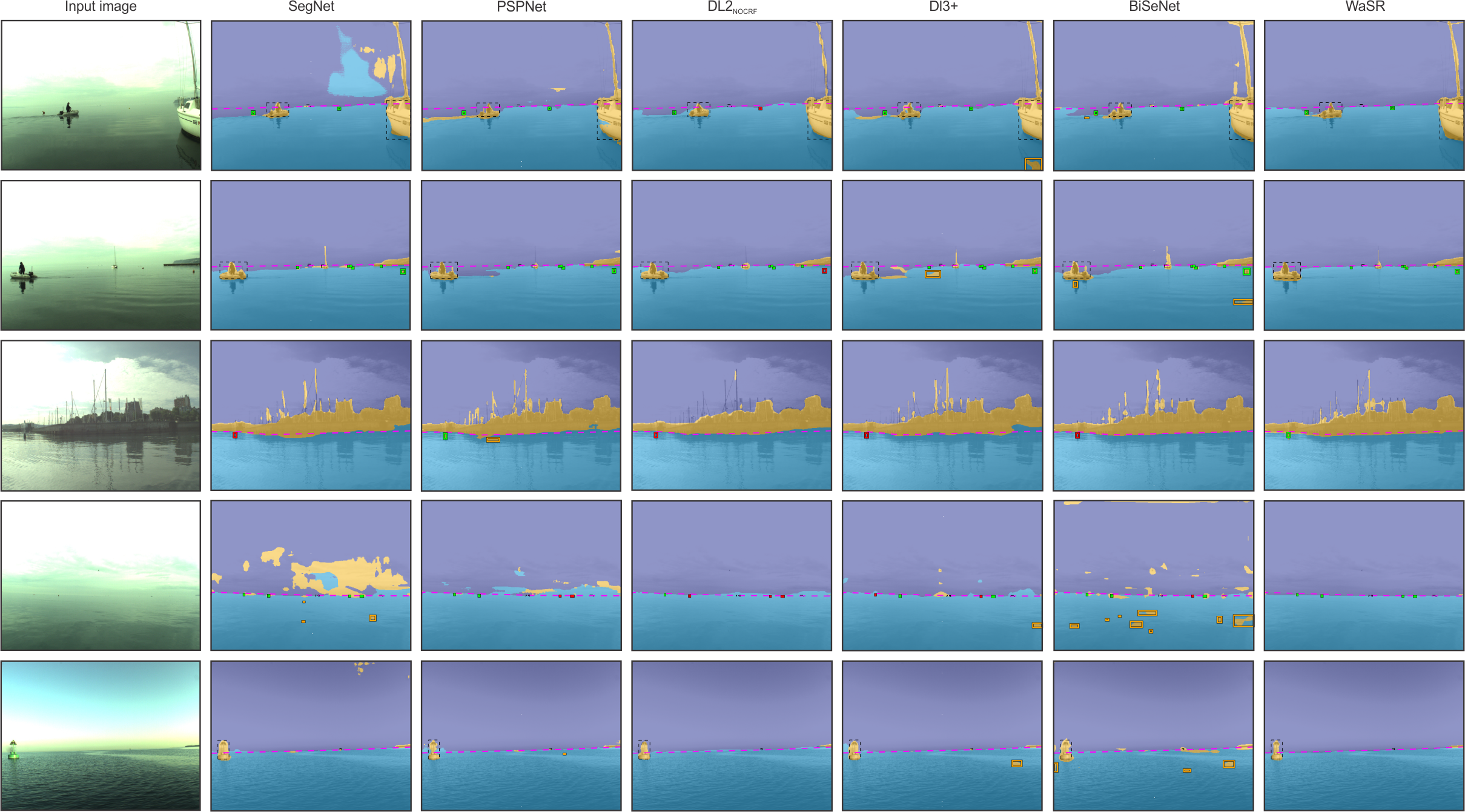
References
-
Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla. "Segnet: A deep convolutional encoder-decoder architecture for image segmentation."
IEEE transactions on pattern analysis and machine intelligence 39.12 (2017): 2481-2495. -
Bovcon, Borja, Jon Muhovič, Janez Perš, and Matej Kristan. "Improving vision-based obstacle detection on USV using inertial sensor."
Proceedings of the 10th International Symposium on Image and Signal Processing and Analysis. IEEE, 2017. -
Bovcon, Borja, Jon Muhovič, Janez Perš, and Matej Kristan. "Stereo obstacle detection for unmanned surface vehicles by IMU-assisted semantic segmentation."
Robotics and Autonomous Systems 104 (2018): 1-13. -
Bovcon, Borja, and Matej Kristan. "Obstacle Detection for USVs by Joint Stereo-View Semantic Segmentation."
2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018. -
Bovcon, Borja, Jon Muhovič, Janez Perš, and Matej Kristan. "The MaSTr1325 dataset for training deep USV obstacle detection models."
2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019. -
Chen, Liang-Chieh, et al. "Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs."
IEEE transactions on pattern analysis and machine intelligence 40.4 (2017): 834-848. -
Chen, Liang-Chieh, et al. "Encoder-decoder with atrous separable convolution for semantic image segmentation."
Proceedings of the European conference on computer vision (ECCV). 2018. -
Deng, Jia, et al. "Imagenet: A large-scale hierarchical image database."
IEEE conference on Computer Vision and Pattern Recognition (CVPR). 2009. -
Everingham, Mark, et al. "The pascal visual object classes (voc) challenge."
International journal of computer vision 88.2 (2010): 303-338. -
Glorot, Xavier and Bengio, Yoshua. "Understanding the difficulty of training deep feedforward neural networks."
Proceedings of the thirteenth international conference on artificial intelligence and statistics (2010): 249-256 -
Kristan, Matej, et al. "Fast image-based obstacle detection from unmanned surface vehicles."
IEEE transactions on cybernetics 46.3 (2015): 641-654. -
Yu, Changqian, et al. "Bisenet: Bilateral segmentation network for real-time semantic segmentation."
Proceedings of the European Conference on Computer Vision (ECCV). 2018. -
Zhao, Hengshuang, et al. "Pyramid scene parsing network."
Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.